目录[+]
Top
什么是Core ML
Core ML是苹果新推出的,面向开发者的机器学习框架。开发者能够轻松实现实时物体识别、人脸特征点识别、跟踪运动中的物体、文本分析等。
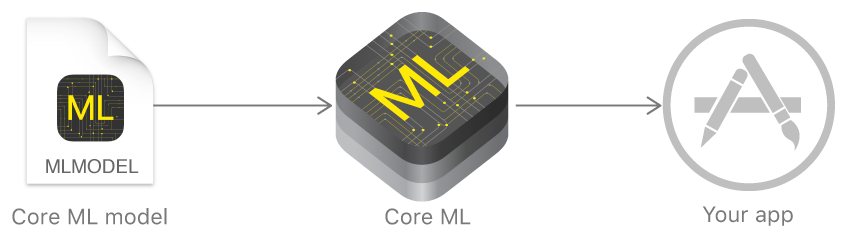
Core ML 让你将很多机器学习模型集成到你的app中。除了支持层数超过30层的深度学习之外,还支持决策树的融合,SVM(支持向量机),线性模型。由于其底层建立在Metal 和Accelerate等技术上,所以可以最大限度的发挥 CPU 和 GPU 的优势。你可以在移动设备上运行机器学习模型,数据可以不离开设备直接被分析,在一定程度上可以为开发者节省购买服务器的成本。而且该框架让所有的机器学习计算都在iOS设备本地进行,这一点依旧体现出苹果对用户隐私很看重。

Vision:高性能的图像分析和图像识别。这部分应用于人脸追踪,人脸识别,文本识别,区域识别,二维码识别,物体追踪,图像识别等。 * Nattural Language processing:自然语言处理。用于语言识别,分词,词性还原,词性判定等。 * GamePlayKit*:游戏制作,构建游戏。用于常见的游戏行为如随机数生成、人工智能、寻路、和代理行为。
如何使用Core ML
不得不提的是CoreML使用起来非常方便。苹果很聪明的定义了一个标准的模型格式(.mlmodel),提供了流行的框架模型到该格式的转换工具, 比如你可以将你的Caffe模型转换成CoreML的模型格式。这样就可以利用各个模型的训练阶段,而不像TensorflowLite只能使用Tensorflow模型。模型训练好了之后,只要拖放到Xcode中就可以使用,苹果甚至把接口的Swift代码都给你生成好了,非常方便。
Step1
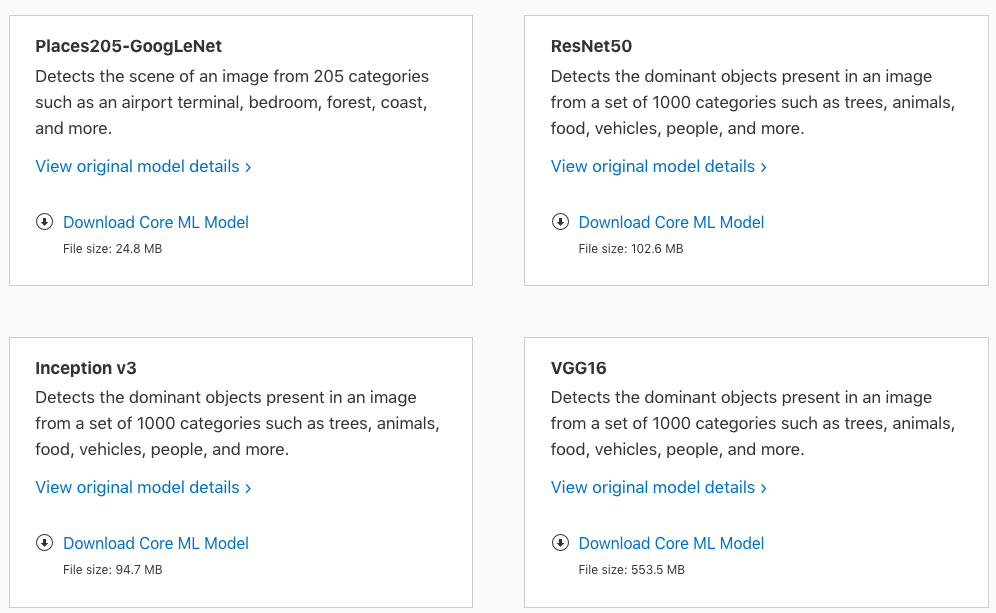
准备好你的模型(.mlmodel),可以按照上面的方法制作你所需的模型,也可以直接在Apple开发者网站上下载现成的模型:
Step2
新建Project,把格式化的模型文件拖入到项目当中,这里下载的是Places205-GoogLeNet.mlmodel,然后点击该model,可以看到:
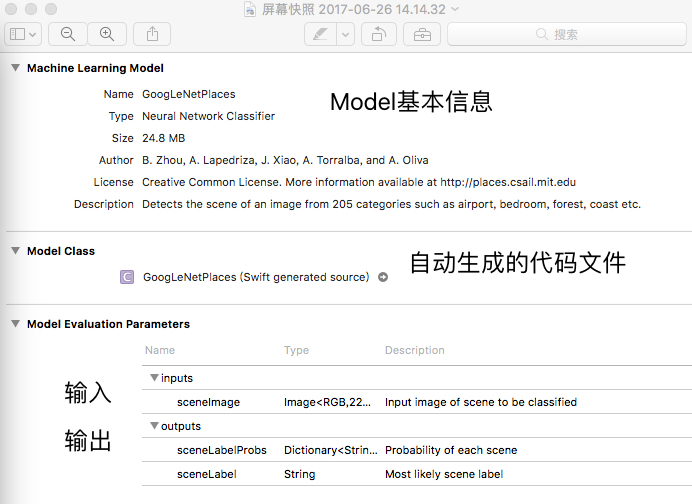
从上图可以看到 CoreML Model 分成三部分,第一部分算是基本的描述,第二部分 ModelClass 是对应 Model 生成的 Source 点击 GoogLeNetPlaces (Swift generated source) 末尾的小箭头进入GoogLeNetPlaces.Swift 文件 可以看到对应 Model的类和方法如下:
-
GoogLeNetPlacesInput:识别输入参数
class GoogLeNetPlacesInput : MLFeatureProvider -
GoogLeNetPlacesOutput:输出鉴定结果
class GoogLeNetPlacesOutput : MLFeatureProvider -
GoogLeNetPlaces:封装输入输出
@objc class GoogLeNetPlaces:NSObject
Step3
使用Xcode自动生成的类及方法
let leNetPlaces = GoogLeNetPlaces()
let image = UIImage.init(named: "timg")
let vnCoreModel = try! VNCoreMLModel.init(for: leNetPlaces.model)
let vnCoreMLRequest = VNCoreMLRequest.init(model: vnCoreModel) { (request:VNRequest, error:Error?) in
guard let result = request.results as? [VNClassificationObservation] else{
fatalError("Requset Error")
}
for classification in result {
if classification.confidence > 0.8 {
//confidence 识别率,值越高越接近
//identifier 识别结果
print(classification.identifier)
print(classification.confidence)
}
}
}
let vnImageRequestHandler = VNImageRequestHandler.init(cgImage: (image?.cgImage)!)
guard(try? vnImageRequestHandler.perform([vnCoreMLRequest])) != nil else {
fatalError("Error!")
}
这里使用了Vision库中的VNCoreMLModel , VNCoreMLRequest , VNImageRequestHandler。
Vison是苹果在WWDC2017上推出的另一个全新框架,其具有高性能的图像分析和计算机视觉能力,应用于图像和视频分类的场景中识别面孔和检测功能。
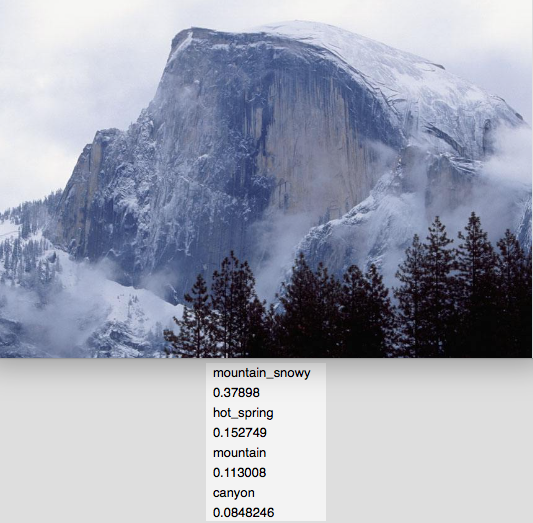
下面来看一下识别结果如何:
一些疑问
- 在模型训练阶段,在尽可能不收集用户数据的前提下,如何优化模型?既使像苹果在去年的 WWDC 上宣称的「我们不需要收集所有用户拍的照片,才知道山长什么样子」,也依然不能回避的事实是,在模型的调优方面,少不了大量的数据支撑。想从 95% 的水平提升到 99% 的水平,数据还是不可缺少的一环。
- 在模型应用阶段,如何做到尽可能在设备本地完成处理?早期受限于设备的性能和功耗,特别是移动设备的电量问题,许多公司选择将数据上传至云端后,由云端服务器来进行运算,只将结果返回给终端设备。
总结下来,苹果的目标,就是在尽可能不收集用户数据的基础上,也能调校出足够好用的模型,同时尽可能只在消费者的设备本地运用模型进行计算处理。而对从业者来说,如何利用好这一优秀条件创造出更好的应用也至关重要。
